

예전 고스락 티켓 서비스 프로젝트에서 관리자 페이지를 만들 때
프론트엔드에서 페이지네이션을 구현하면서
페이지마다 필요한 데이터들을
백엔드에서 어떻게 넘기는지에 대해 알고싶었는데
마침 이번 TIFY 프로젝트에서
질문에 대한 답변 조회, 현재 로그인 한 유저의 친구 목록 조회 페이지네이션을 맡게 되었다.
페이지네이션 방법 중
(TIFY는 모바일 앱이기 때문에)
모바일 앱에 더 적합한 무한 스크롤을 적용하기로 하였다.
코드는 아래 Github PR에 자세히 나와있다.
feat: 친구 목록 조회 무한스크롤 API 작성 by bongsh0112 · Pull Request #38 · Team-TIFY/TIFY-SERVER
📝 PR Summary feat: 친구 목록 조회 무한스크롤 API 작성 🌲 Working Branch feat/37-neighborlist 🌲 TODOs querydsl 오류 수정 코드 리뷰 Related Issues close #37
github.com
0) 페이지네이션
[참고] Infinite Scrolling vs. Pagination
페이지네이션은 콘텐츠를 여러 페이지로 나누어
다음 또는 이전 페이지로 이동하거나 특정 페이지로 이동할 수 있는 기능이다.
콘텐츠의 크기가 클 때 페이지를 몇 개의 덩어리로 나누어
이전, 다음 페이지로 넘어가는 것을 페이지네이션이라고 한다.
페이지네이션 구현 시
성능을 개선할 수 있는 기법이 있는데
필자는 무한 스크롤을 사용하였고,
다른 대표적인 기법이 커버링 인덱스이다.
0-1) 무한 스크롤

무한 스크롤이란
크기가 큰 콘텐츠 덩어리를 끝없이 스크롤할 수 있게 하는 기능이다.
사실 무한 스크롤을 페이지네이션의 일부로 보는 것이
제대로 된 범주화인지는 잘 모르겠지만
무한 스크롤이 크기가 큰 콘텐츠를 덩어리로 나눠놓고
페이지를 아래로 스크롤할 때
페이지를 계속 새로 고치면서 데이터를 보여준다는 점이
페이지네이션과 비슷한 로직이라고 생각이 든다,,
0-2) 커버링 인덱스
커버링 인덱스에 들어가기 전,
아래 더보기에 인덱스에 대해 간단히 정리해보자.
인덱스란?
데이터들의 주소를 가지고 있는 값으로,
데이터베이스에서 특정 데이터에 빠르게 접근할 수 있도록 하는
DB에서의 포인터이다.
EX) user_id를 인덱스로 삼으면 user_id에 해당하는 레코드들의 주소값이 각 user_id마다 할당된다.
이후 user_id로 user 조회 시 조건으로 주어진 user_id 인덱스에서 주소를 찾고
그 주소에 담긴 데이터를 불러온다.
데이터의 정보를 가지는 데이터 파일과는 별개로
인덱스는 인덱스 파일 이라는 곳에 Hash Table 또는 Binary-Tree(+)로 구성되어있으며
이 파일에 데이터들의 주소 정보를 가지는 인덱스들의 정보가 저장되어있다.
커버링 인덱스란?
쿼리를 작성했을 때
그 쿼리를 충족하는데 필요한 모든 데이터를 갖는 인덱스를 말한다.
말이 어려운데, 풀어서 설명하면
SELECT, WHERE, ORDER BY, GROUP BY 등에 사용되는 모든 컬럼들이
인덱스의 구성요소로 포함되는 것이다.
코드로 예시를 들어보자면 다음과 같다.
CREATE INDEX `email_id_age` ON `member` (email, id, age);
SELECT email, id, age
FROM member
WHERE email LIKE 'bong%' # where 절에 email 존재
GROUP BY id, age; # group by 절에 id, age 존재
페이징 쿼리에 커버링 인덱스를 이용하면
훨씬 더 빠른 조회가 가능해지기 때문에
다음 페이지 버튼이나 어떤 특정 페이지 버튼을 누르면
그 페이지에 들어갈 콘텐츠들을 모두 가져오는
일반적인 페이지네이션 구현에서 더 빠른 다음 페이지 로딩이 가능해진다.
1) Slice vs. Page
무한 스크롤 API를 작성할 때 가장 크게 고려한 점은
어떻게 데이터들을 덩어리로 묶을 것인가? 였다.
Java에서는 동적 페이징을 위해
Page와 Slice 객체를 지원하는데
Page 객체는 페이징 후 모든 데이터의 개수를 불러오고
Slice 객체는 페이징만 수행한다.
카페 글 게시판처럼 총 게시글의 갯수가 필요하다면 Page 객체가 좋겠지만
필자가 구현해야 하는 무한 스크롤의 경우 그럴 필요가 없기 때문에
Slice를 사용했다.
1-1) SliceResponse
Slice 객체를 사용하기 위해
record 객체인 SliceResponse를 직접 구현하였다.
요청에 대한 응답으로 반환될 객체이기 때문에
API 모듈에 작성했다.
public record SliceResponse<T>(List<T> content, long page, int size, boolean hasNext) {
public static <T> SliceResponse<T> of(Slice<T> slice) {
return new SliceResponse<>(
slice.getContent(),
slice.getNumber(),
slice.getNumberOfElements(),
slice.hasNext());
}
}순수 데이터 클래스인 record를 이용해서
Slice 객체를 받으면
SliceResponse로 바꾸어주는 메소드인 of를 정의했다.
record 클래스의 특성 상 따로 생성자를 정의해 줄 필요가 없기 때문에
위같은 코드를 작성할 수 있다.
1-2) SliceUtil
public class SliceUtil {
public static <T> Slice<T> valueOf(List<T> contents, Pageable pageable) {
boolean hasNext = hasNext(contents, pageable);
return new SliceImpl<>(
hasNext ? getContent(contents, pageable) : contents, pageable, hasNext);
}
private static <T> boolean hasNext(List<T> content, Pageable pageable) {
return pageable.isPaged() && content.size() > pageable.getPageSize();
}
private static <T> List<T> getContent(List<T> content, Pageable pageable) {
return content.subList(0, pageable.getPageSize());
}
}
/**
* SliceImpl 참고
*/
public SliceImpl(List<T> content, Pageable pageable, boolean hasNext) {
super(content, pageable);
this.hasNext = hasNext;
this.pageable = pageable;
}
public SliceImpl(List<T> content) {
this(content, Pageable.unpaged(), false);
}Slice 객체를 사용하기 위한 SliceUtil 클래스이다.
이 클래스에서는 어떤 Slice 객체를 불러올 때
그 객체가 다음 콘텐츠를 가지고 있는지 판단하여
마지막 콘텐츠만 내려줄지 SliceImpl(List<T> content)
다음 콘텐츠에 대한 정보를 내려줄지 결정한다. SliceImpl(List<T> content, Pageable pageable, boolean hasNext)
이 클래스는 Domain 모듈의 Repository에서
쿼리로 페이징한 것들을 Slice의 형태로 바꾸어주는 클래스이므로
Domain 모듈에 작성하였다.
2) 무한 스크롤 코드 작성
2-1) UserController
@Operation(summary = "친구 목록 조회")
@GetMapping("/neighbors")
public SliceResponse<RetrieveNeighborDTO> getNeighbors(
@ParameterObject @PageableDefault(size = 10) Pageable pageable) {
return retrieveNeighborListUseCase.execute(pageable);
}
현재 로그인된 유저와 친구인 유저들의 목록을 조회하는 API이다.
@ParameterObject로 Pageable의 각 필드를
분리된 queryParameter로 받을 수 있게 하였다.
page에 3, size에 3을 넣으면
9페이지부터 12페이지 전까지 세 개의 페이지가 나올 것이다.
2-2) NeighborCondition
@Getter
@AllArgsConstructor
public class NeighborCondition {
Long currentUserId;
private Pageable pageable;
}이 클래스는 찾아야 할 친구들의 조건을 설정한다.
이번 API의 경우 현재 로그인된 사용자의 친구들을 무한 스크롤 페이지네이션하는 것이므로
현재 사용자의 ID와 Pageable 객체를 넣어주었다.
2-3) RetrieveNeighborDTO
@Getter
@AllArgsConstructor
public class RetrieveNeighborDTO {
private Long neighborId;
private String neighborUserId;
private String neighborThumbnail;
private String neighborName;
private String neighborBirth;
private String onBoardingStatus;
private Long order;
private boolean isView;
}API를 이용하여 받아야 하는 데이터들을 DTO로 묶었다.
나와 친구인 사용자의 정보들과
친구 목록에서 보여지는 order(목록에서의 순서),
친구 숨김 여부를 결정하는 isView를 포함한 클래스를 포함한다.
2-4) RetrieveNeighborListUseCase
@UseCase
@RequiredArgsConstructor
public class RetrieveNeighborListUseCase {
private final NeighborAdaptor neighborAdaptor;
private final UserAdaptor userAdaptor;
private final UserUtils userUtils;
@Transactional(readOnly = true)
public SliceResponse<RetrieveNeighborDTO> execute(Pageable pageable) {
Long currentUserId = userUtils.getUserId();
NeighborCondition neighborCondition = new NeighborCondition(currentUserId, pageable);
Slice<RetrieveNeighborDTO> neighborDTOS =
neighborAdaptor.searchNeighbors(neighborCondition);
return SliceResponse.of(neighborDTOS);
}
}UseCase에서는 현재 사용자의 id값을 가져와
neighborAdaptor의 custom respository에서 만든 쿼리를 사용하여
NeighborCondition에 맞게 가져온 DTO들을
SliceResponse로 바꾸어 리턴한다.
2-5) NeighborCustomRepositoryImpl
@RequiredArgsConstructor
public class NeighborCustomRepositoryImpl implements NeighborCustomRepository {
private final JPAQueryFactory queryFactory;
@Override
public Slice<RetrieveNeighborDTO> searchToPage(NeighborCondition neighborCondition) {
List<RetrieveNeighborDTO> neighbors =
queryFactory
.select(
Projections.constructor(
RetrieveNeighborDTO.class,
neighbor.toUserId,
user.userId,
user.profile.thumbNail,
user.profile.userName,
user.profile.birth,
user.onBoardingStatus.name,
neighbor.order,
neighbor.isView))
.from(neighbor)
.join(user)
.on(user.id.eq(neighbor.toUserId))
.where(neighbor.fromUserId.eq(neighborCondition.getCurrentUserId()))
.orderBy(neighbor.order.asc())
.offset(neighborCondition.getPageable().getOffset())
.limit(neighborCondition.getPageable().getPageSize() + 1)
.fetch();
return SliceUtil.valueOf(neighbors, neighborCondition.getPageable());
}
}DTO에 지정된 필드들을 DB로부터 가져오는
CustomRepositoryImpl 클래스이다.
neighbor의 fromUserId와 현재 로그인한 유저의 ID를 맞춰주고
neighbor의 toUserId와 user의 ID를 맞추어
현재 로그인한 유저의 친구인 유저들의 정보를 가져온다.
페이징을 위해 offset과 limit을 정해주며
limit에는 항상 1을 더해주는 것을 잊지 말자.
3) 테스트
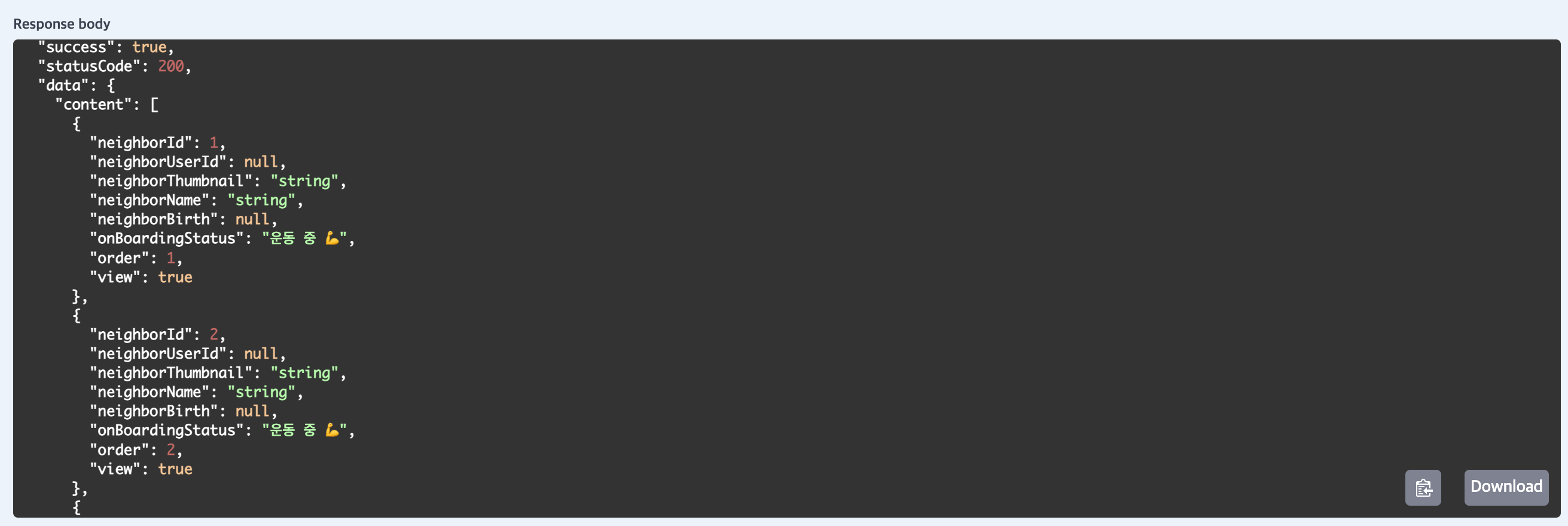
설계한 대로 잘 나오는 것을 볼 수 있다.
그런데 이 방식대로 한다면
만약 스크롤을 내리는 도중 데이터가 추가된다면
추가된 데이터는 조회하지 못하는 경우가 발생할 수도 있다.
이 때는 SliceResponse에 추가하여 Redis로 캐싱을 하는 방법이 있다고 하는데
이것을 추후에 공부해보고 사용해보려 한다.
'🌿 Spring' 카테고리의 다른 글
| [Spring] 전략 패턴 사용하기 (0) | 2024.01.29 |
|---|---|
| 메일 발송 - 스케쥴링 간 문제 해결 with Async (1) | 2023.10.03 |
| 등록된 미술품 상태 변경 with Scheduling (0) | 2023.10.03 |
| 사용자에게 메일 보내기 with JavaMailSender (0) | 2023.10.03 |