
MVP 임에도
열정적인 기획분들 덕분에 상품 테이블의 데이터 개수가
3000개가 넘어가게 되었다.
DB에 등록되어있는 상품을 검색할 때
아직까지는 시간이 그렇게 오래걸리지는 않으나
계속해서 프로젝트를 업데이트를 하다 보면
언젠가는 상품의 개수가 만개, 혹은 훨씬 더 많아질 것 같다고 생각했다.
이런 생각을 하고 있을 때
마침 프론트 쪽에서도 상품 검색의 성능이 조금 떨어지는 것 같다는 의견을 주어서
같은 백엔드 팀원인 민준이와 DB 인덱싱을 통해 검색 기능의 성능을 개선해보기로 하였다.
검색을 구현한 자세한 코드는 아래 레포지토리에서 찾아볼 수 있다.
GitHub - Team-TIFY/TIFY-SERVER: TIFY 팀 서버 레포지토리입니다.
TIFY 팀 서버 레포지토리입니다. Contribute to Team-TIFY/TIFY-SERVER development by creating an account on GitHub.
github.com
0) DB 인덱스란?
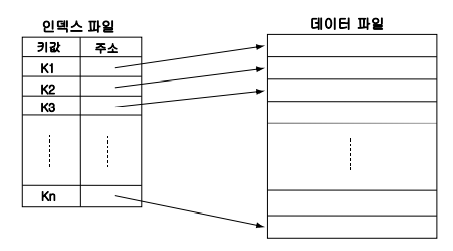
DB 인덱스란 DB 저장 자료구조 중 하나로,
실제 레코드를 저장하는 데이터 파일 이외에
레코드들에 대한 포인터(주소)를 저장하는 인덱스 파일을 따로 만들고
그것을 이용해 DB 테이블의 검색 성능을 개선시킬 수 있다.
인덱스의 종류는 크게 세 가지이다.
클러스터 인덱스와 보조 인덱스,
그리고 그 둘을 합쳐서 사용하는 인덱스가 그것이다.
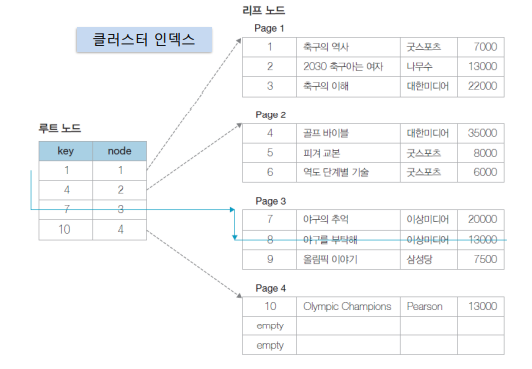
- 클러스터 인덱스 : 인덱스의 리프 노드 == 데이터 레코드인 인덱스 방법. 레코드들의 물리적인 저장 순서가 인덱스 순서와 동일하게 되도록 구성된 인덱스로, 찾고자 하는 레코드의 key값(A)과 정해진 key값을 갖는 루트 노드의 key값(B)을 비교하여 A > B 라면 B 노드가 가리키는 리프 노드보다 더 큰 key값을 가지는 리프 노드를 탐색한다. 검색에 있어 보조 인덱스보다 성능이 좋다.
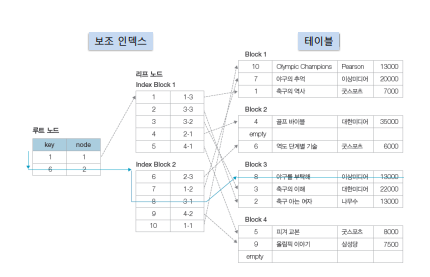
- 보조 인덱스 : 인덱스의 리프 노드 == 데이터 레코드의 주소 목록인 인덱스 방법. 클러스터 인덱스와 같은 규칙을 가지고 루트 노드의 key값과 레코드의 key 값을 비교한 후 리프노드에서 레코드의 주소를 찾아간다. 클러스터 인덱스보다 한 단계를 더 거치기 때문에 검색은 느리나, 수정, 삭제, 삽입이 더 빠르다.
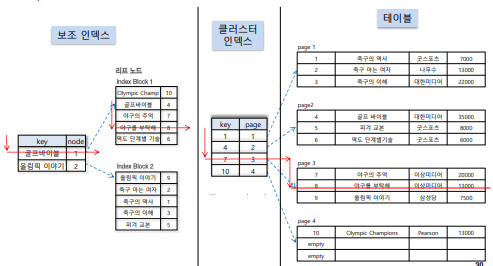
- 보조 + 클러스터 인덱스 : 보조 인덱스로 key값을 찾고, 얻어낸 key값을 가지고 클러스터 인덱스를 이용하여 검색해낸다.
인덱싱을 하지 않으면
기본적으로 힙 파일(Heap File)을 이용한
순차 방법을 이용하는데, 순차 방법에서의 삽입, 삭제, 검색은 아래와 같이 수행된다.
- 삽입 : 새로운 레코드는 일반적으로 파일의 가장 끝에 삽입됨. 파일 중간에 반환된 빈 공간인 자유공간에도 삽입 가능.
- 삭제 : 레코드들이 삭제된 후에 빈 공간들을 회수해서 자유 공간에 반환함.
- 검색 : 원하는 레코드를 찾기 위해서는 모든 레코드들을 순차적으로 접근해야함.
1) 인덱스 적용하기
1-1) 인덱스 적용 전
상품 검색에 쓰이는 QueryDSL 문은 아래와 같다.
public Slice<ProductRetrieveDTO> searchBySmallCategory(
ProductCategoryCondition productCategoryCondition) {
List<ProductRetrieveDTO> products =
queryFactory
.select(
Projections.constructor(
ProductRetrieveDTO.class, product, favorQuestionCategory))
.from(product)
.join(favorQuestionCategory)
.on(product.favorQuestionCategoryId.eq(favorQuestionCategory.id))
.where(
product.favorQuestionCategoryId.in(
productCategoryCondition.getCategoryIdList()),
priceBetween(productCategoryCondition.getPriceFilter()))
.orderBy(orderByPrice(productCategoryCondition.getPriceOrder()))
.offset(productCategoryCondition.getPageable().getOffset())
.limit(productCategoryCondition.getPageable().getPageSize() + 1)
.fetch();
return SliceUtil.valueOf(products, productCategoryCondition.getPageable());
}
private OrderSpecifier[] orderByPrice(PriceOrder priceOrder) {
List<OrderSpecifier> orderSpecifiers = new ArrayList<>();
if (priceOrder.equals(PRICE_ASC)) {
orderSpecifiers.add(new OrderSpecifier(Order.ASC, product.price));
} else if (priceOrder.equals(PRICE_DESC)) {
orderSpecifiers.add(new OrderSpecifier(Order.DESC, product.price));
} else {
orderSpecifiers.add(new OrderSpecifier(Order.ASC, product.id));
}
return orderSpecifiers.toArray(new OrderSpecifier[orderSpecifiers.size()]);
}
private BooleanExpression priceBetween(PriceFilter priceFilter) {
if (priceFilter.equals(LESS_THAN_10000)) {
return product.price.between(0L, 9999L);
} else if (priceFilter.equals(MORE_THAN_10000_LESS_THAN_30000)) {
return product.price.between(10000L, 29999L);
} else if (priceFilter.equals(MORE_THAN_30000_LESS_THAN_50000)) {
return product.price.between(30000L, 49999L);
} else if (priceFilter.equals(MORE_THAN_50000)) {
return product.price.between(50000L, MAX_VALUE);
} else {
return product.price.between(0L, MAX_VALUE);
}
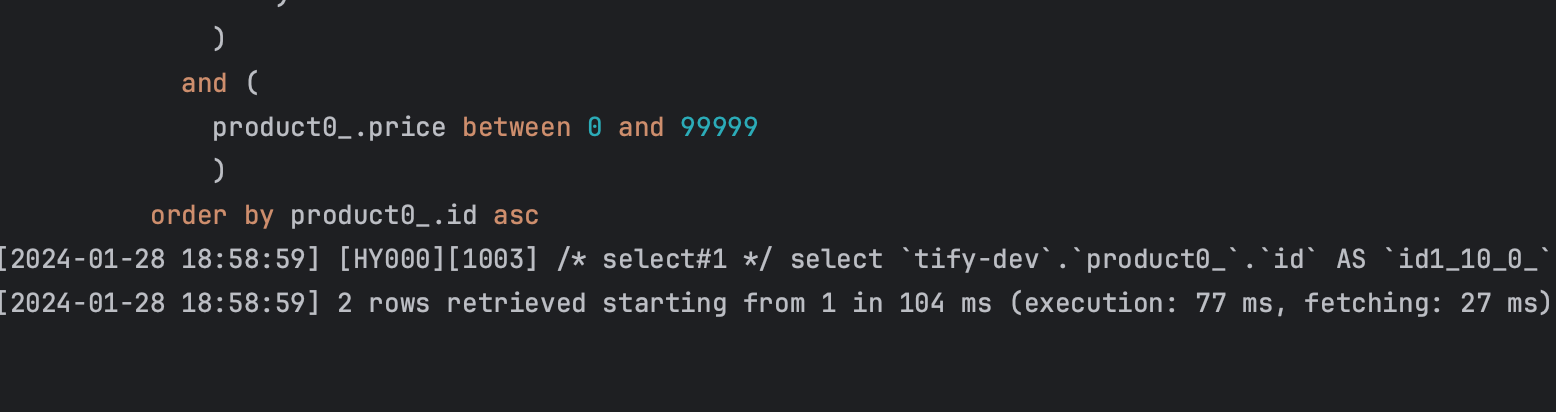
}이를 실행시켰을 때 나오는 실제 쿼리를 찍어보니 다음과 같았다.
select product0_.id as id1_10_0_,
favorquest1_.id as id1_6_1_,
product0_.created_at as created_2_10_0_,
product0_.updated_at as updated_3_10_0_,
product0_.brand as brand4_10_0_,
product0_.characteristic as characte5_10_0_,
product0_.crawl_url as crawl_ur6_10_0_,
product0_.favor_question_category_id as favor_qu7_10_0_,
product0_.image_url as image_ur8_10_0_,
product0_.name as name9_10_0_,
product0_.price as price10_10_0_,
product0_.product_option as product11_10_0_,
product0_.site as site12_10_0_,
favorquest1_.created_at as created_2_6_1_,
favorquest1_.updated_at as updated_3_6_1_,
favorquest1_.detail_category as detail_c4_6_1_,
favorquest1_.large_category as large_ca5_6_1_,
favorquest1_.name as name6_6_1_,
favorquest1_.small_category as small_ca7_6_1_
from tbl_product product0_
inner join
tbl_favor_question_category favorquest1_ on (
product0_.favor_question_category_id = favorquest1_.id
)
where (
product0_.favor_question_category_id in (
1, 2
)
)
and (
product0_.price between 0 and 99999
)
order by product0_.id asc;
## 1, 2, 0, 99999와 같은 값은 필자가 임의로 넣은 값이 쿼리문을 explain 하여 분석해보니...
explain 설명 보기 -> MySQL 공식문서
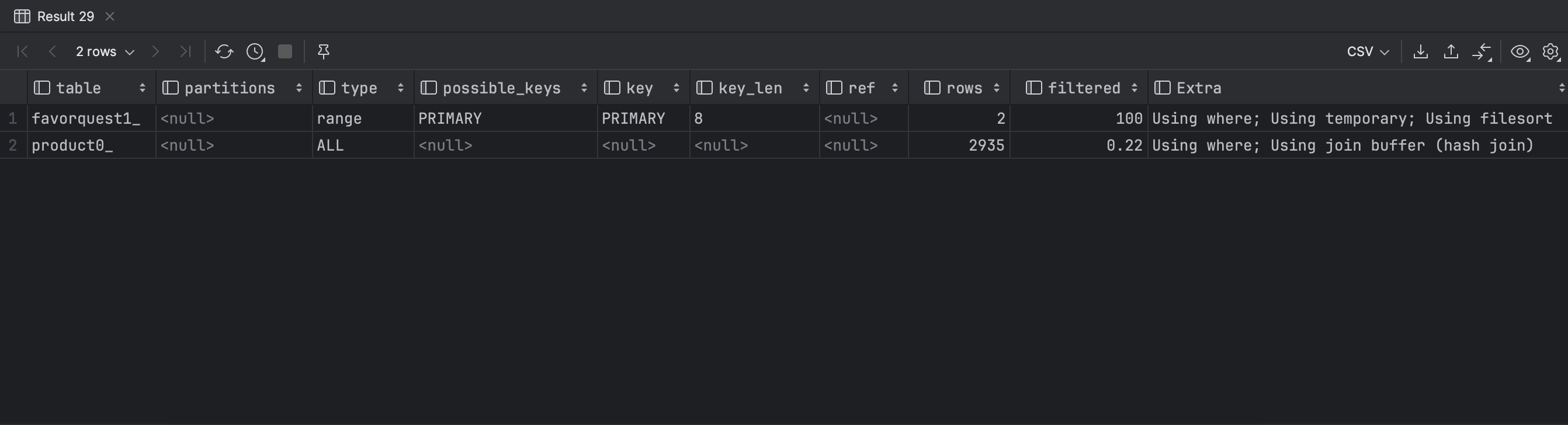
민준이가 얘기하길,
type이 ALL이 나오면 그냥 실무에서는 x된거라고 볼 수 있단다..
워낙 간단한 쿼리라서 시간도 얼마 안 걸리는 것이지,
만약 복잡한 쿼리문이라면 실행 시간도 오래 걸릴 것이고,
3000개밖에 없는 테이블에서부터 오래 걸리면
몇십만 몇백만개의 레코드가 있는 테이블에선 거의 장애 수준으로 오래 걸릴 것이다.
1-2) 인덱스 적용 과정
인덱스의 핵심은,
어떤 컬럼을 인덱스화 하여
검색 성능을 개선시키는지를 파악하는 것이다.
민준이는 일반적으로 where 절에 들어가 조건이 되는 컬럼을 골라
인덱싱하는 것이 가장 바람직한 것이라고 말했다.
필자가 작성한 쿼리문의 where 절을 보면
tbl_product 테이블의 favor_question_category_id와 price가 조건으로 붙는다.
따라서 index 생성 쿼리문을 이렇게 작성해보면..
create index example1
on tbl_product(favor_question_category_id, price);
1-3) 인덱스 적용 후 성능 체크
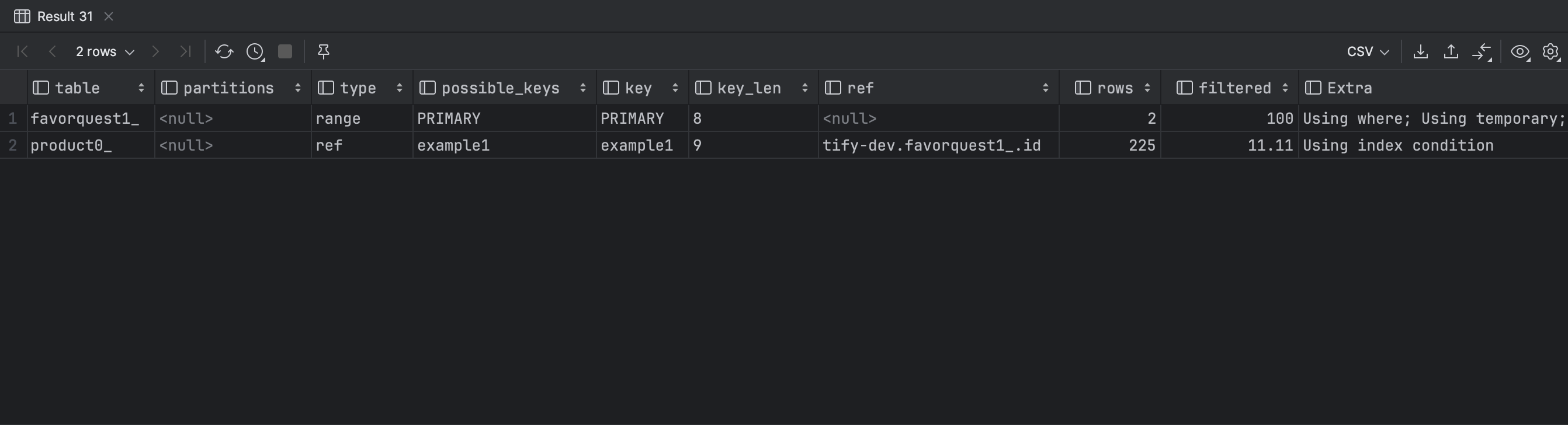
확실히 rows와 실행 시간은 줄었으나,
filtered는 어째서인지 늘어났다.
join 할 때도 인덱스를 적용하면 더 성능이 좋으려나.. 라고 생각했지만
생각해보면 어차피 join의 조건이 pk 비교인데.. pk 인덱스는 원래 있는건데..
filtered에 대해서는 더 공부가 필요할 것 같다.
역시 학교에서 배우기만 하면
몸으로 와닿지 않는데,,,
실제로 써보니 왜 쓰는지 알겠드라...
프로젝트 리팩토링을 하면서
인덱스를 써서 다이나믹한 성능 개선이 있으면 계속해서 이 포스팅에 추가해나가야지 ㅎㅎ
'🎉 프로젝트 > 🎁 TIFY' 카테고리의 다른 글
| [TIFY] Apple Login 구현 시 OIDC 사용하기 (1) | 2024.01.16 |
|---|---|
| [TIFY] AWS S3 생성 및 Presigned URL 도입 (0) | 2024.01.15 |
| [TIFY] Selenium을 이용한 올리브영 크롤링 in SpringBoot (0) | 2023.08.23 |
| [TIFY] Slack WebHook으로 Spring 500에러 알림 받기 (0) | 2023.07.04 |