

사용자들의 취향에 따른 선물 아이템들을 추천해주는 TIFY의 특성 상,
위와 같이 상품의 이미지들을 하나하나 DB에 입력하는 것은
너무나도 공수가 크다고 판단되었다.
이를 해결하기 위해 Selenium을 이용하여 크롤링을 하기로 하였다.
코드는 아래 Github PR에 자세히 나와있다.
feat: 올리브영 크롤링 구현 by bongsh0112 · Pull Request #33 · Team-TIFY/TIFY-SERVER
📝 PR Summary 올리브영 크롤링을 구현합니다. 🌲 Working Branch feat/32-crawling 🌲 TODOs Related Issues #32
github.com
0) Selenium이란?
코드를 작성하여 웹 브라우저를 동작시키는 웹사이트 테스트 도구로
웹 어플리케이션 테스트와
반복되는 웹 기반 관리 작업을 자동화시킬 수 있는 툴이다.
위와 같은 특징 때문에,
동적 페이지를 사용하는 웹 사이트를 크롤링할 때 많이 채택된다.
Selenium 말고도 크롤링에 많이 쓰이는 툴인
Jsoup은 정적 페이지를 사용하는 웹 사이트를 크롤링하는 데에 더 적합하다.
1) SpringBoot에 의존성 추가
서버 내부 자원이 아닌 외부 자원을 끌어다 쓰는 방식이므로
Infrastructure 모듈에 의존성을 추가해주었고
코드 또한 해당 모듈에 작성하였다.
dependencies {
api 'org.seleniumhq.selenium:selenium-java:4.1.2'
}
2) Chromedriver 사용하기
Selenium은 브라우저 드라이버를 사용하기 때문에
크롬 드라이버를 설치해주어야 한다.
Java로 크롤링하며 macOS를 쓰는 레퍼런스를 찾기 힘들어서 구글링을 해가며 환경을 구성했다.
2-1) Chromedriver 설치
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
chromedriver.chromium.org
Chromedriver는 Chrome 브라우저의 버전에 맞는 것으로 선택하여 설치해야 한다.
버전이 맞지 않으면 Chromedriver를 사용하는 Selenium은 당연히 작동하지 않는다.

Chrome 브라우저의 설정에 들어가서
Chrome 정보를 확인하면 내 Chrome의 버전을 볼 수 있다.
이에 맞는 Chromedriver를 위 링크에서 다운받으려했으나
Chrome 버전이 너무 최신이라 그에 맞는 최적화된 버전이 없는듯 했다.....
https://googlechromelabs.github.io/chrome-for-testing/
Chrome for Testing availability
chrome-headless-shellmac-arm64https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/118.0.5963.0/mac-arm64/chrome-headless-shell-mac-arm64.zip404
googlechromelabs.github.io
최신 Chrome에 맞는 Chromedriver는 위 링크에서 제공된다.
zip 파일을 다운받고 압축을 풀어보면 다음과 같은 실행파일과 LICENSE 파일이 나온다.

실행파일을 실행시키면 Chromedriver가 실행되어야 하는데
앱 개발자를 신뢰할 수 없다면서 실행 못하게 하더라..
(이건 코드를 직접 실행시켜봤을 때 알게 되었다 ㅠㅠ)

xattr -d com.apple.quarantine chromedriver위 명령어를 Chromedriver 실행파일이 있는 디렉토리에서
입력해주면 설정이 끝난다.
위 방법 말고도 brew로 설치한 Chromedriver를 사용할 수 있는데,
그 방법은 다음 더보기에 있다.
# brew로 chromedriver 다운받기
brew install --cask chromedriver
우선 homebrew로 Chromedriver를 다운받는다.
brew로 install하여도 위 방법처럼 개발자를 신뢰할 수 없는 것은 마찬가지다.
따라서 brew가 Chromedriver를 어디에 다운받았는지 알아내고
다운받은 디렉토리에 가서 실행 허용을 해주어야 한다.
# brew가 chromedriver를 어디에 다운받았는지 알아내기
brew info chromedriver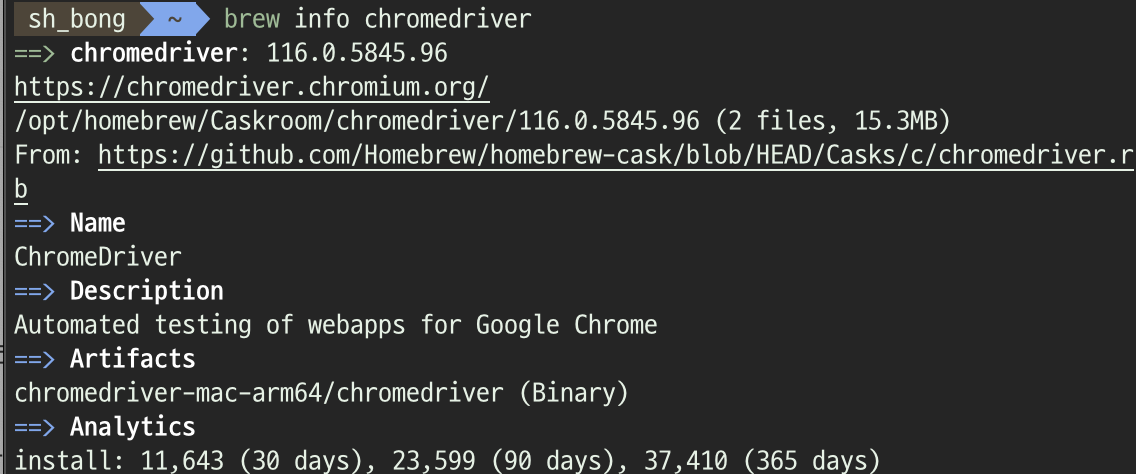
/opt/homebrew/Caskroom/chromedriver/116.0.5845.96/chromedriver-mac-arm64까지 들어가서
신뢰 허용 명령어를 입력해주면 된다.
위 폴더 안에 chromedriver 실행 파일이 있기 때문에,,
2-2) Chromedriver를 실행시키는 절대 경로 설정하기
위 단계에서 Chromedriver를 brew를 사용하지 않고 직접 설치했다면,
경로는 대체로 다음과 같을 것이다.
/Users/{사용자}/Downloads/chromedriver-mac-arm64/chromedriver만약 chromedriver 실행 파일을 다른 곳에 옮겼다면
그곳에서도 개발자 신뢰 명령어를 입력해야하고
그곳의 경로를 절대 경로로 설정해야 한다.
만약 brew를 사용하여 설치했다면
경로는 대체로 다음과 같을 것이다.
/opt/homebrew/Caskroom/chromedriver/{chrome version}/chromedriver-mac-arm64/chromedriver이제 이 경로를 가지고 코드를 작성해보자.
3) 크롤링 코드 작성
https://www.selenium.dev/documentation/webdriver/elements/finders/#find-elements-from-element
Finding web elements
Locating the elements based on the provided locator values.
www.selenium.dev
WebElement들에 대한 메소드는 Selenium 공식 문서를 참조했다.
위에서 한번 서술했듯이 외부 서버 자원을 사용하므로
Infrastructure 모듈에 클래스를 작성했다.
3-1) OliveYoungCrawl
우선 올리브영 상품 상세 페이지는 API를 이용하고
https://www.oliveyoung.co.kr/store/G.do?goodsNo={상품번호}
이러한 형식으로 queryParameter를 받는 동적 페이지이다.
우리가 이 페이지에서 크롤링을 통해 받아올 데이터는
기획 쪽과 협의를 한 결과 우선은
상품의 이름과 상품의 대표 이미지 정도이다.
메이크업 카테고리를 예로 들면
어떤 사이트에서 상품 상세 페이지에서 찾을 수 있는 요소들 중
상품 이름, 이미지와 같은 뎁스가 얕은 것부터
상품 옵션(상품 색깔 등), 상품 특징과 같은 뎁스가 깊은 것들 모두 크롤링이 필요하다는 것을 들었으나
이는 공수가 클 것 같아 우선 뎁스가 얕은 것부터 크롤링해보기로 하였다.

위 단계에서 기억해놓은 chromedriver의 절대 경로를 이용하여
System의 property를 설정해준다.
@Component
@RequiredArgsConstructor
public class OliveYoungCrawl {
private WebDriver driver;
private static final String url = "https://www.oliveyoung.co.kr/store/G.do?goodsNo=";
public Map<String, String> process(List<String> productCodes) {
System.setProperty(
"webdriver.chrome.driver",
"/Users/{user}/Downloads/chromedriver-mac-arm64/chromedriver");
ChromeOptions options = new ChromeOptions();
options.addArguments("--remote-allow-origins=*"); // 원격 드라이버가 URL에 접근하도록 허용
driver = new ChromeDriver(options); // chromedriver에 option 넣어주기
Map<String, String> dataList = new HashMap<>();
try {
dataList.putAll(getDataList(productCodes));
} catch (InterruptedException e) {
throw FeignException.EXCEPTION;
// feign을 이용하므로 FeignException(미리 정의해둔 Exception이다)
}
driver.close();
driver.quit();
return dataList;
}
private Map<String, String> getDataList(List<String> productCodes) throws InterruptedException {
Map<String, String> map = new HashMap<>();
Thread.sleep(1000);
productCodes.forEach(
productCode -> {
driver.get(url + productCode);
String prdName = driver.findElement(By.className("prd_name")).getText();
String imgSrc = driver.findElement(By.id("mainImg")).getAttribute("src");
map.put(prdName, imgSrc);
});
return map;
}
}이 클래스에서는 크롤링을 수행하여
주어진 일련번호(productCodes)에 대한 상품 이름(prdName)과 대표 이미지(imgSrc)를
HashMap 형태로 반환한다.
Chromedriver에 위와 같이 작성된 option을 넣어주어
원격으로 연결된 Chrome 브라우저에 Chromedriver가 URL에 접근할 권한을 준다.
크롤링을 할 때 Chromedriver는 다른 가상의 브라우저 창을 열어
그곳에서 데이터를 찾아오는데,
이 창이 열리는 시간을 벌기 위해 Thread.sleep(1000)을 이용한다.

img 태그의 id로 element를 찾아 src attribute의 값을 가져오고
상품 이름은 prd_name이라는 class를 가진 태그의 text를 가져오도록 하였다.
가져온 값들은 Map에 상품이름 : 대표이미지 형식으로 저장되어 반환된다.
3-2) ProductController
@RestController
@RequiredArgsConstructor
@RequestMapping("/products")
public class ProductController {
private final OliveYoungCrawl oliveYoungCrawl;
@Operation(summary = "올리브영 크롤링을 통해 상품명과 상품 이미지를 가져옵니다.")
@PatchMapping("/oliveyoung")
public void oliveYoungCrawl(
@RequestBody PatchOliveYoungCrawlingRequest patchOliveYoungCrawlingRequest) {
Map<String, String> process =
oliveYoungCrawl.process(patchOliveYoungCrawlingRequest.getProductCodes());
}
}테스트를 위하여 API를 작성해보았다.
추후 다른 사이트에 대한 크롤링 클래스를 작성한다면
테스트 시 더 추가될 예정이다.
RequestBody를 사용해야 하기 때문에
RequestBody를 지원하지 않는 Get 대신
Post 혹은 Patch 메소드를 사용해야했다.
단지 테스트 용이기 때문에
여타 Controller처럼 UseCase는 지정하지 않았다.
(PR에는 나중에 쓸 수도 있을 것 같아 미리 만들어놓은 것!)
3-3) PatchOliveYoungCrawlingRequest
@Getter
@NoArgsConstructor
public class PatchOliveYoungCrawlingRequest {
private List<String> productCodes;
}Controller에서 인자로 RequestBody를 넘겨주어야 하기 때문에
따로 model.request 패키지를 만들어
Body의 형식을 지정했다.
여러 상품의 일련번호를 전달해야하기 때문에
List를 사용했다.
4) 크롤링 하기


RequestBody에 넘겨준 5개의 상품 번호에 대해
크롤링을 진행했다.
위 실행 결과는 따로 출력 코드를 찍어 본 것이고
Map에 저장될 때는 중복되는 값은 제외하고 저장되어 반환 될 것이다.
TIFY의 경우 많은 상품을 크롤링해야 하는데
지금 5개의 상품만 하는데도 시간이 꽤 걸리는 것을 볼 수 있다.
추후에 크롤링 시간을 줄일 수 있는 방법도 알아보아야 하겠다.
'🎉 프로젝트 > 🎁 TIFY' 카테고리의 다른 글
| [TIFY] 검색 기능 성능 개선 with DB index (2) | 2024.01.28 |
|---|---|
| [TIFY] Apple Login 구현 시 OIDC 사용하기 (1) | 2024.01.16 |
| [TIFY] AWS S3 생성 및 Presigned URL 도입 (0) | 2024.01.15 |
| [TIFY] Slack WebHook으로 Spring 500에러 알림 받기 (0) | 2023.07.04 |